|
I am a postdoctoral researcher at Stanford SVL. I received my PhD in Computer Science at Johns Hopkins University in 2026, working with Alan L. Yuille and Rama Chellappa. I study intelligence in the physical world by structuring raw observations into spatial code. My works laid the foundation, spanning vision encoders and world models. I am best known for TransUNet, which unifies local and global context and has over 10,000 citations. I am a Siebel scholar for contributions to bioengineering, a Kempner fellow, and a recipient of several best paper and young investigator awards. |

|
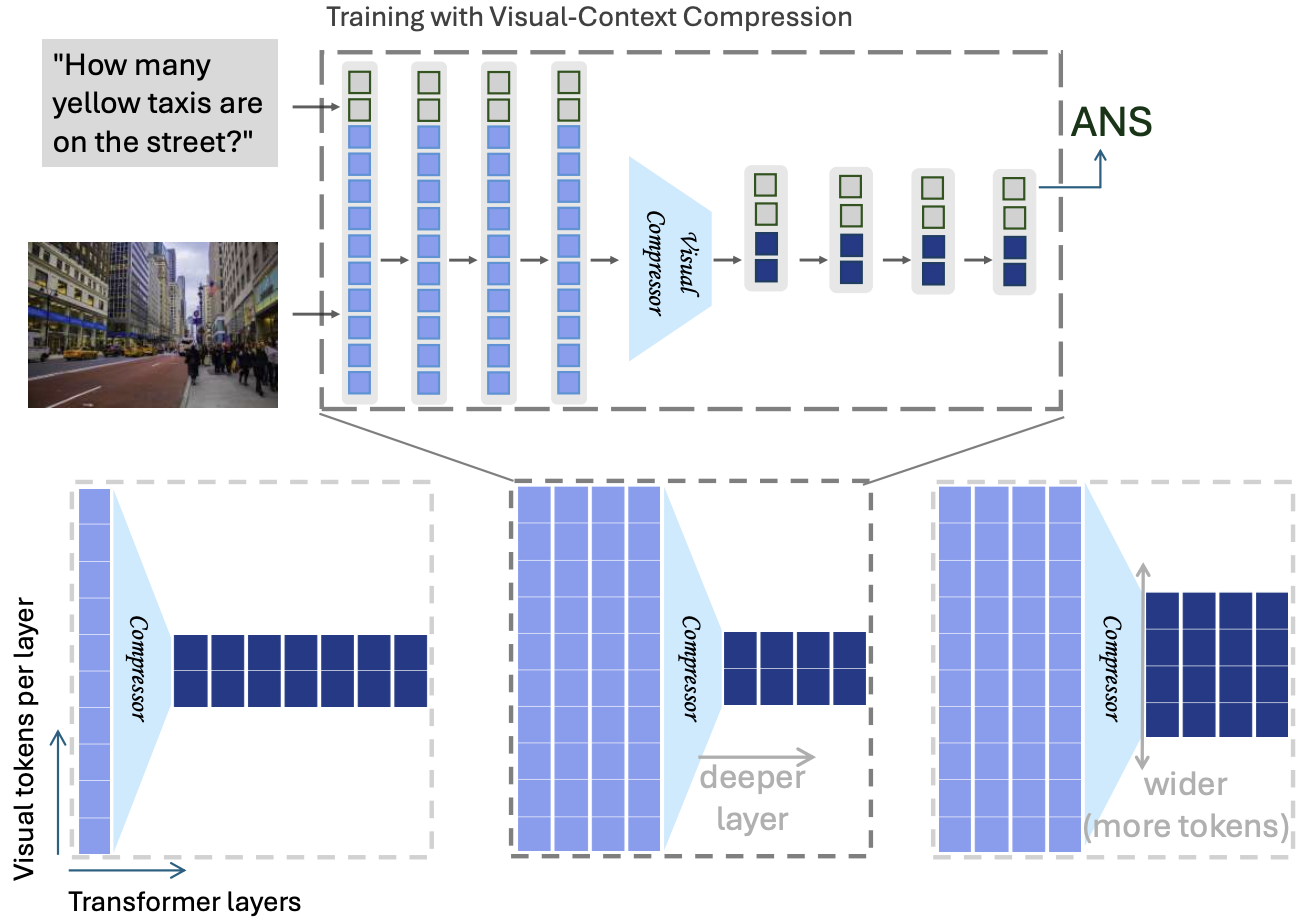
- New paper: Thinking with Spatial Code — new SoTA on VSI-bench for 3D/4D reasoning.
- Co-organizing the 1st CVPR 2026 workshop on World Models Meet Active Sensing and Embodied Planning. Try our benchmark World-in-World (ICLR 2026 Oral).
- Co-organizing the 4th CVPR 2026 workshop on Generative Models for Computer Vision.
- Research opportunities: feel free to email me. I host students through CCVL as well as SVL.
- Siebel Scholar Award, 2025
- MICCAI Best Paper Award , 2025
- MICCAI Doctoral Consortium Thesis Award, 2025
- Young Investigator Best Paper Award — KDD Health Day and CCC, 2025
- Visionary Award, Large Language Model Hackason for Material Science, 2025
- CVPR Doctoral Consortium, 2025
- JHU Provost Thesis Award, 2026
- RSNA Certificate of Merit Award, 2025
- Kempner Research Fellowship, 2026
- NVIDIA 2025 Academic Grant, 2025
- DAAD AInet Fellowship, 2022
- #1 most downloaded article on ScienceDirect; among the most cited in MedIA, 2026
- #1 most cited among all ECCV publications in past five years (Google Metrics), 2026
 ICLR'26 Oral
ICLR'26 Oral
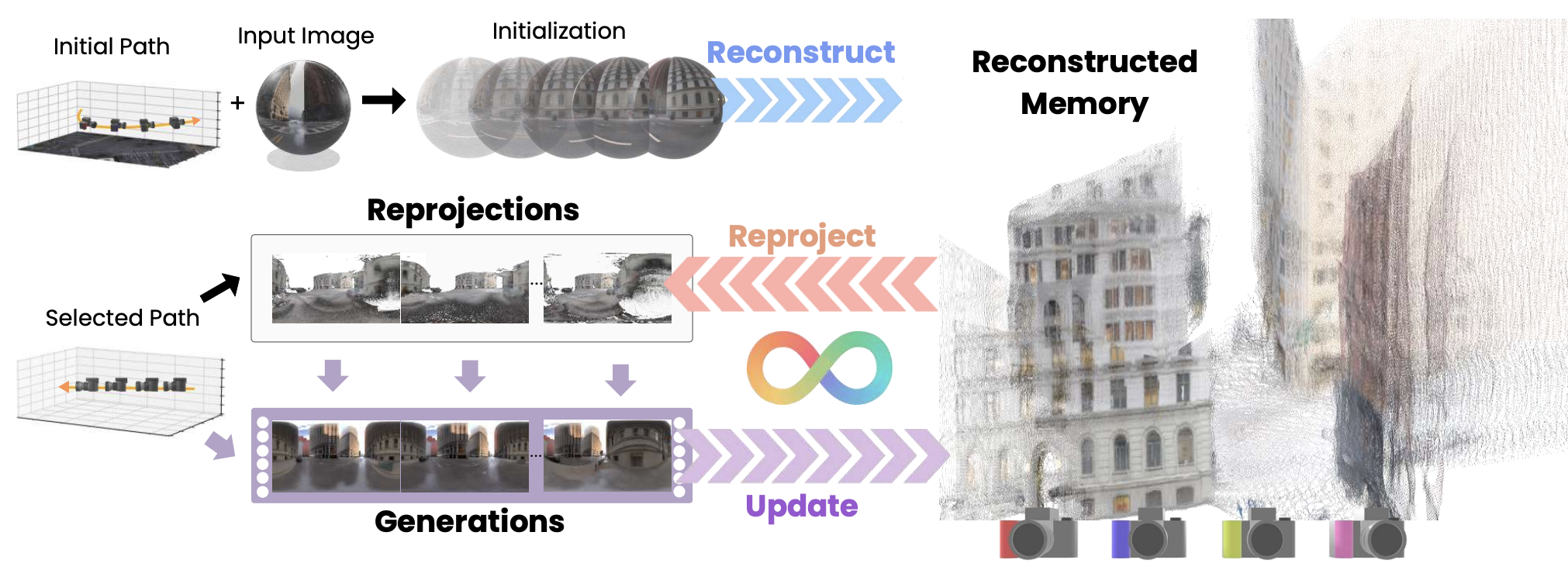
Closed-loop world model — generation, perception & action in the physical world.
Turn a single image into an explorable 3D world. Agents navigate generated environments.
 arXiv'26
arXiv'26
Object-centric causal spatial reasoning benchmark with physics-aware world model evaluation.
Medical World Model — generative tumor evolution simulation for personalised treatment planning.
 CVPR'25 Highlight
CVPR'25 Highlight
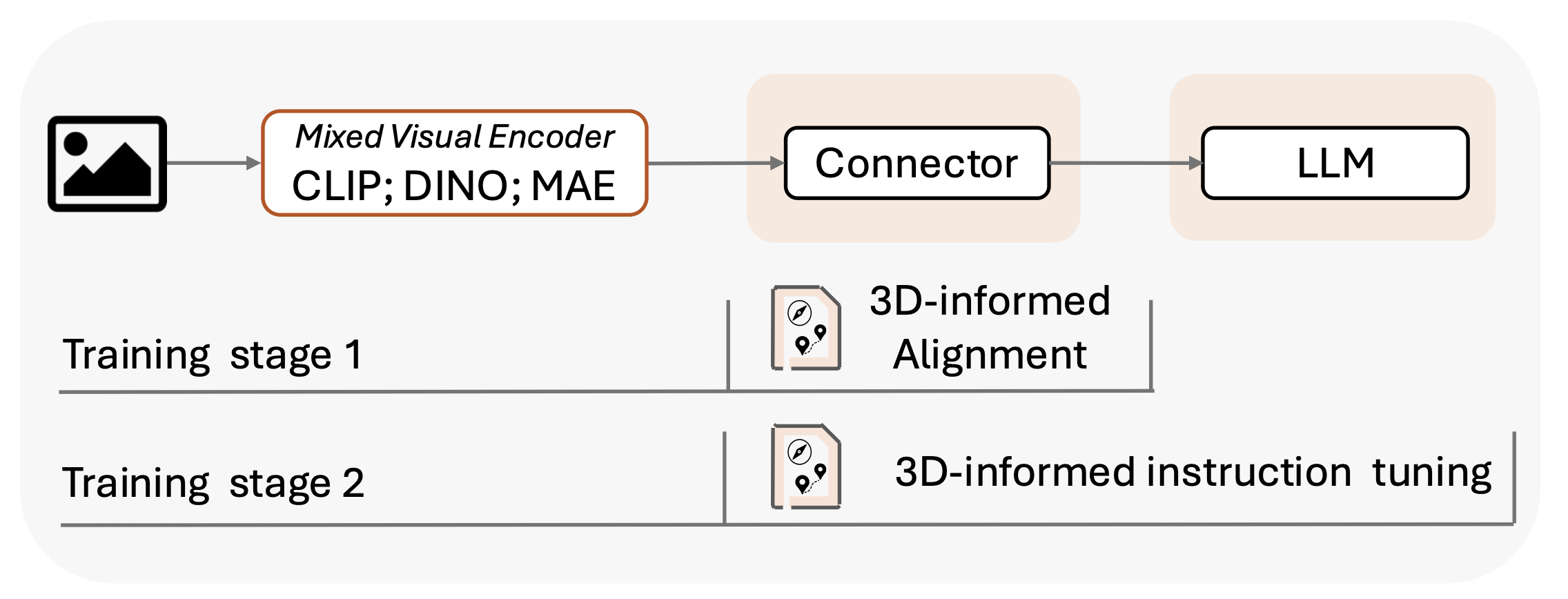
Compound 3D-informed design for spatially-intelligent large multimodal models.
ICLR'26 OralClosed-loop world model — generation, perception & action in the physical world.
Turn a single image into an explorable 3D world. Agents navigate generated environments.
ICLR'26 WMObject-centric causal spatial reasoning benchmark with physics-aware world model evaluation.
Medical World Model — generative tumor evolution simulation for personalised treatment planning.
CVPR'25 HighlightCompound 3D-informed design for spatially-intelligent large multimodal models.
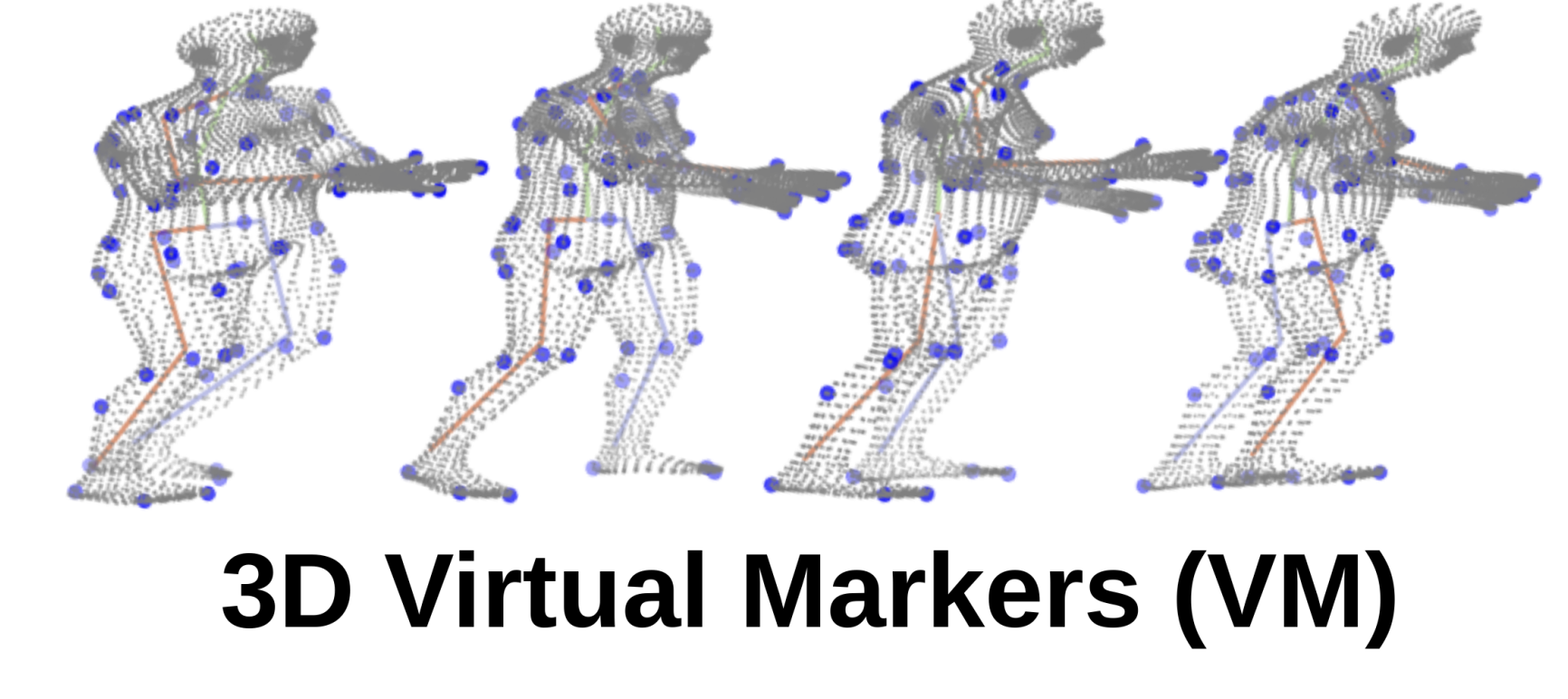
Freely reconstructing animatable 3D animals from monocular video.



{kind=link}
{kind=link}
- Invited talk at NSF IAIFI on physics & AI, Boston.
- Lab seminar at Stanford.
- Vision seminar at UIUC.
- Guest lecture at Rice University.
- Lab seminars at Harvard / MIT / HMS / MGH / Dana-Farber.
- Talk at ICLR 2025 Workshop on Embodied Intelligence with LLMs in Open City Environment (slides).
- Talks at JHU: ChemBE, Cognitive Science, CLSP, MINDS, AIEM.
- Instructor: Machine Imagination (EN.601.208), JHU, 2025 & 2026.
- Reviewer: CVPR, ICCV, ECCV, WACV, NeurIPS, ICML, ICLR, AAAI, IJCV, TPAMI, TMI, MICCAI, CogSci.
- Workshop co-organizer: ICCV, CVPR, MICCAI.
- JHU CS mentor hours.
- Lecture for JHU WSE Pre-College Program 2025.
I am fortunate to have collaborated with talented students at JHU.
-
TaiMing Lu, JHU Undergraduate → Princeton CS PhD
1 publication on GenEx. Michael J. Muuss Research Award; finalist for CRA Outstanding Undergraduate Researcher Award. -
Shanshan Zhong, SYSU MS → CMU LTI PhD
1 publication on 4D-Animal.
My doctoral research was made possible through the generous support of ARL, IARPA, NSF, NIH, ONR, Lambda, NVIDIA, Google Cloud, JHU, Stanford, Harvard, the Siebel Foundation, the Patrick J. McGovern Foundation, and the Lustgarten Foundation.