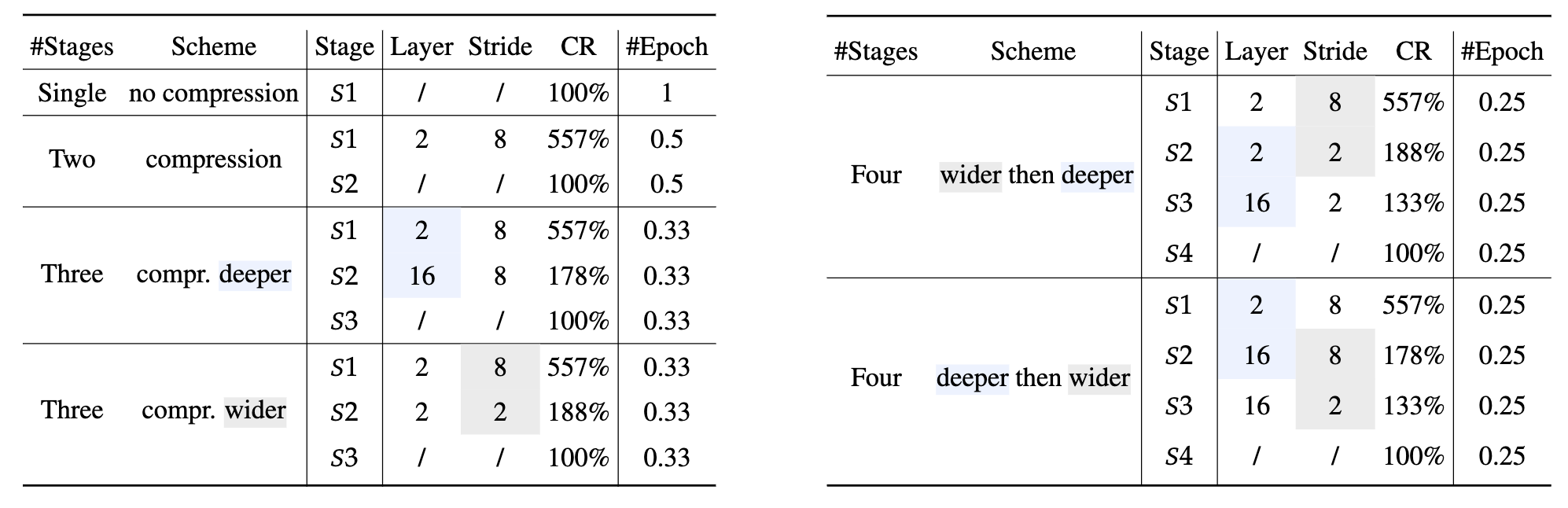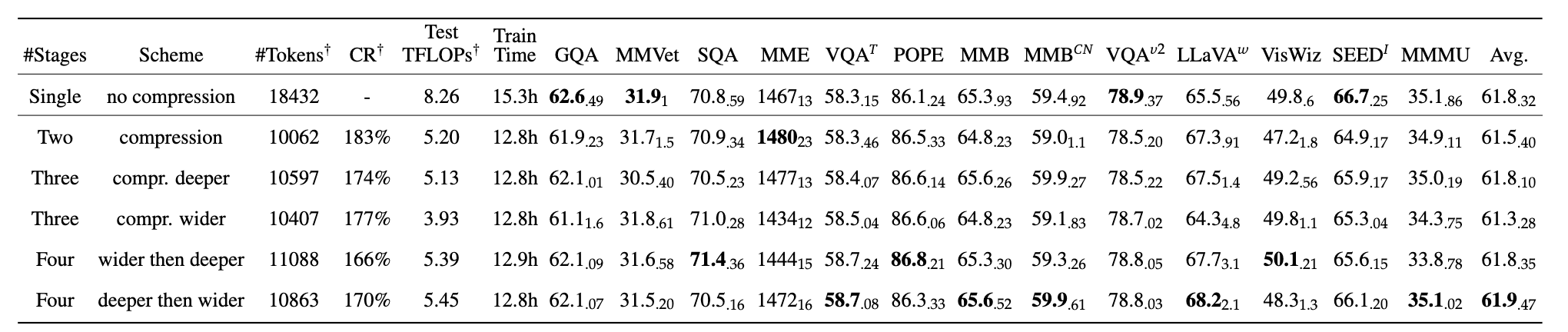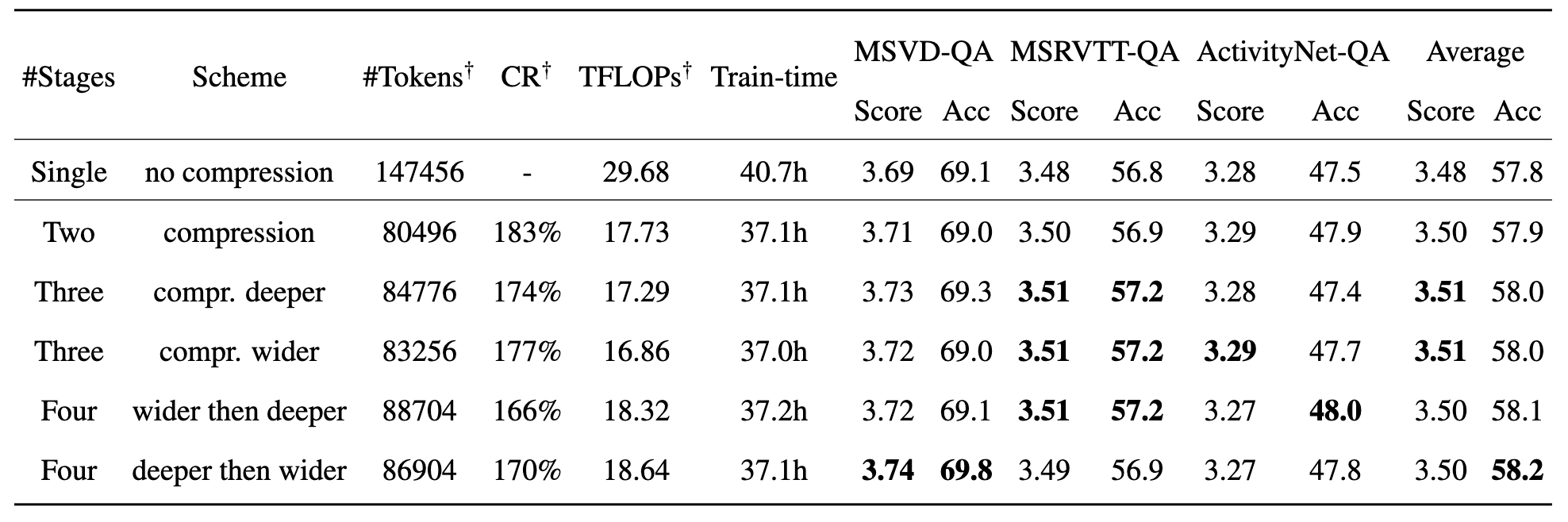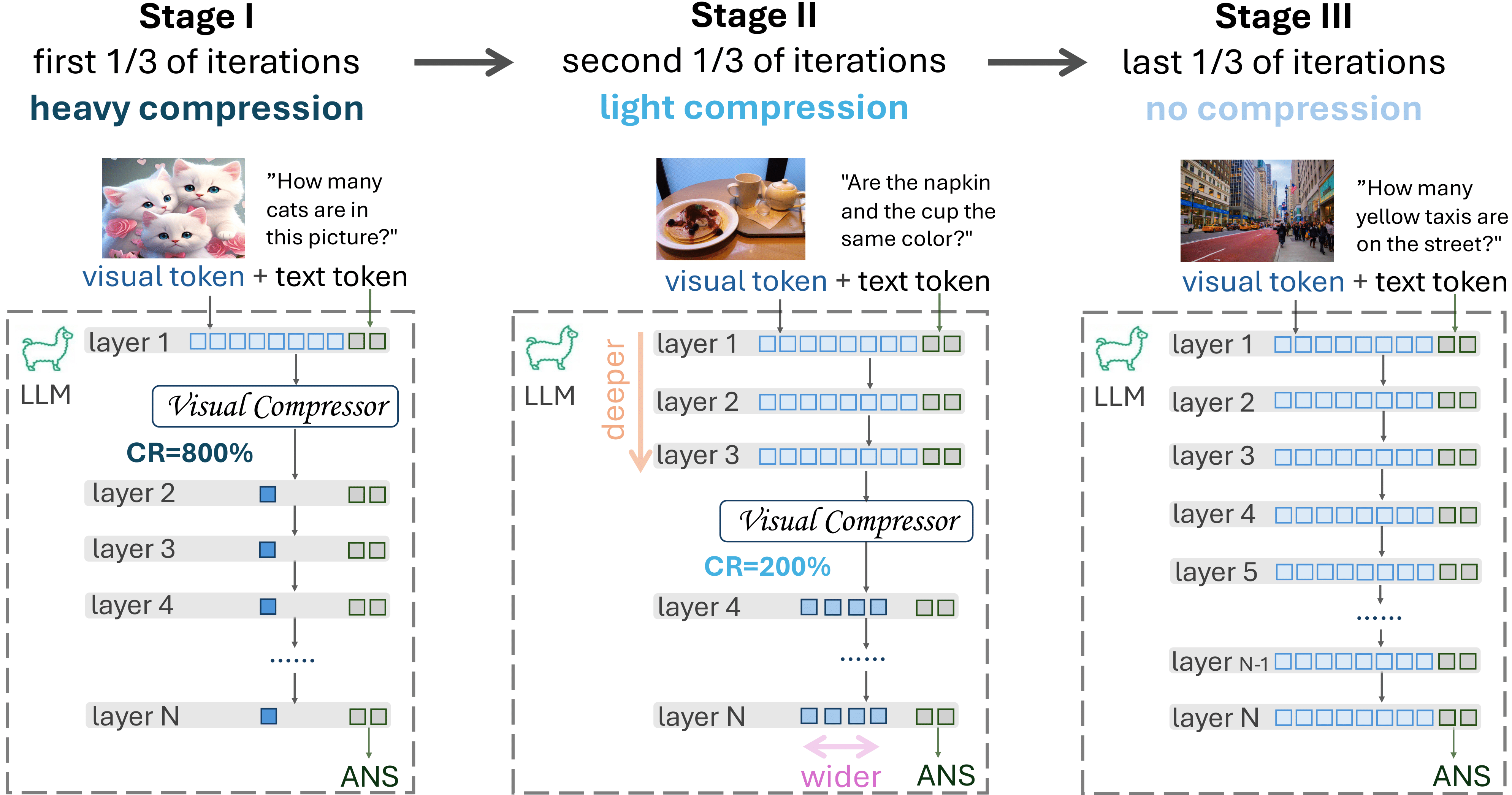
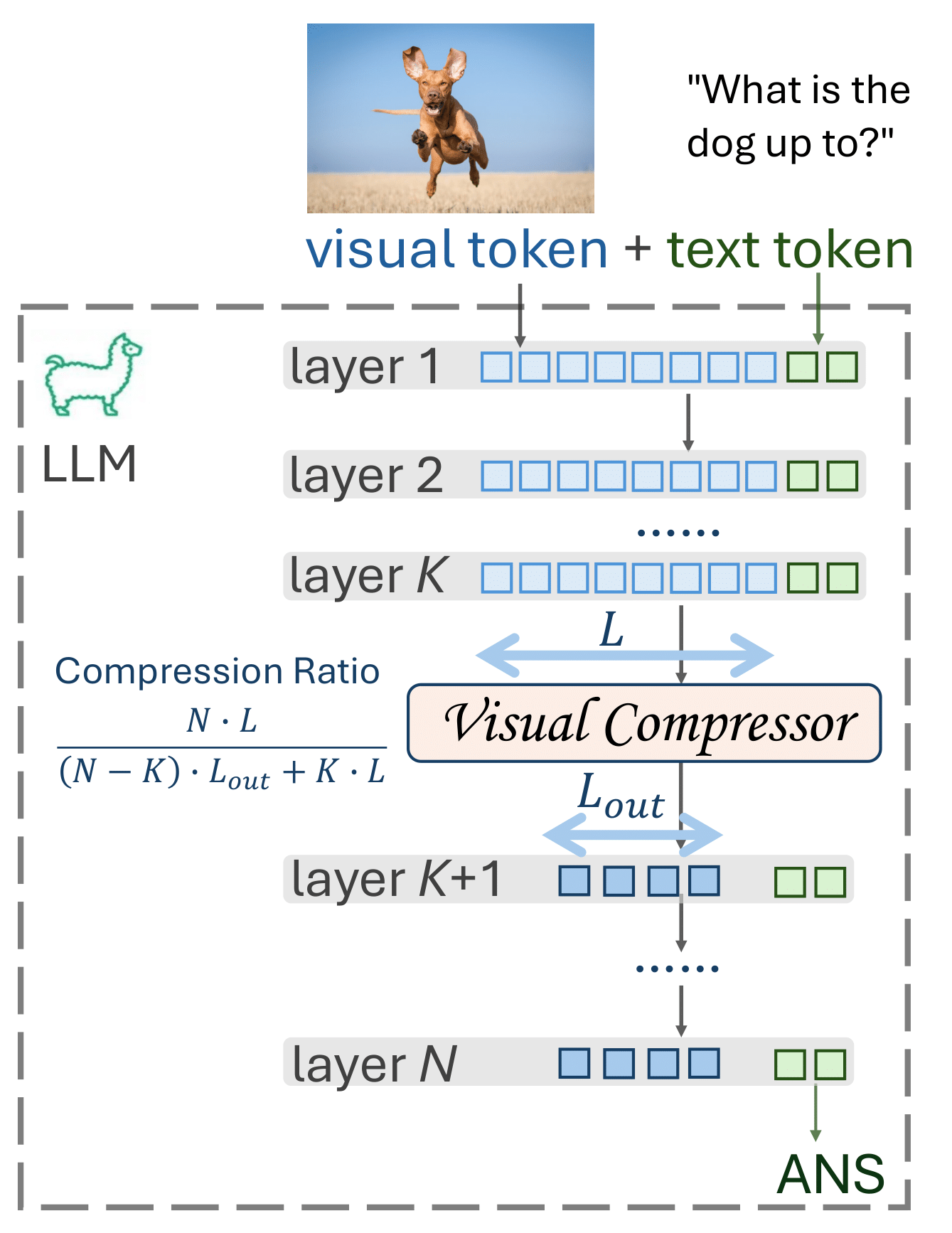
Instantiation of LLaVolta
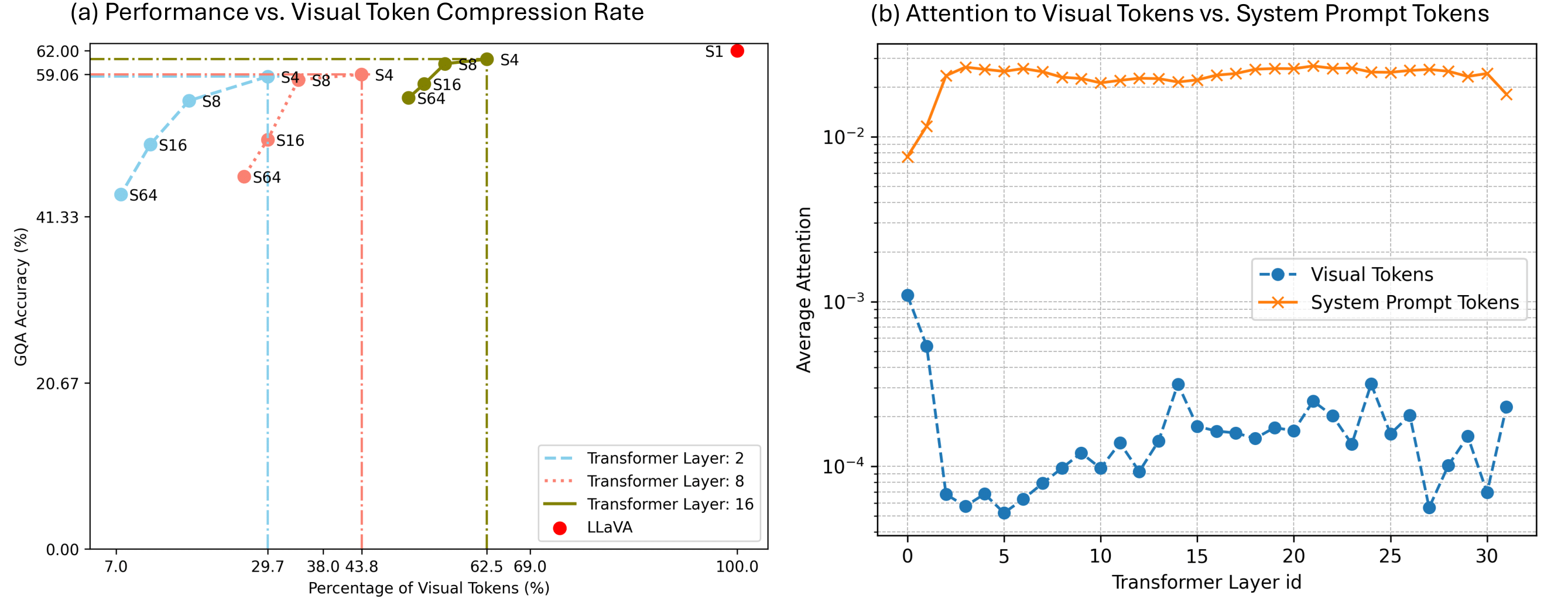
A family of training schemes are instantiated heree. The single-stage (non-compression) scheme is equivalent to the MLLM baseline (LLaVA). For multi-stage training, the compression stage can either go deeper or wider. "deeper" implies an increase in K (Transformer layer), while "wider" means a decrease in the stride of the pooler.