Zero-shot Classification/Retrieval Accuracy
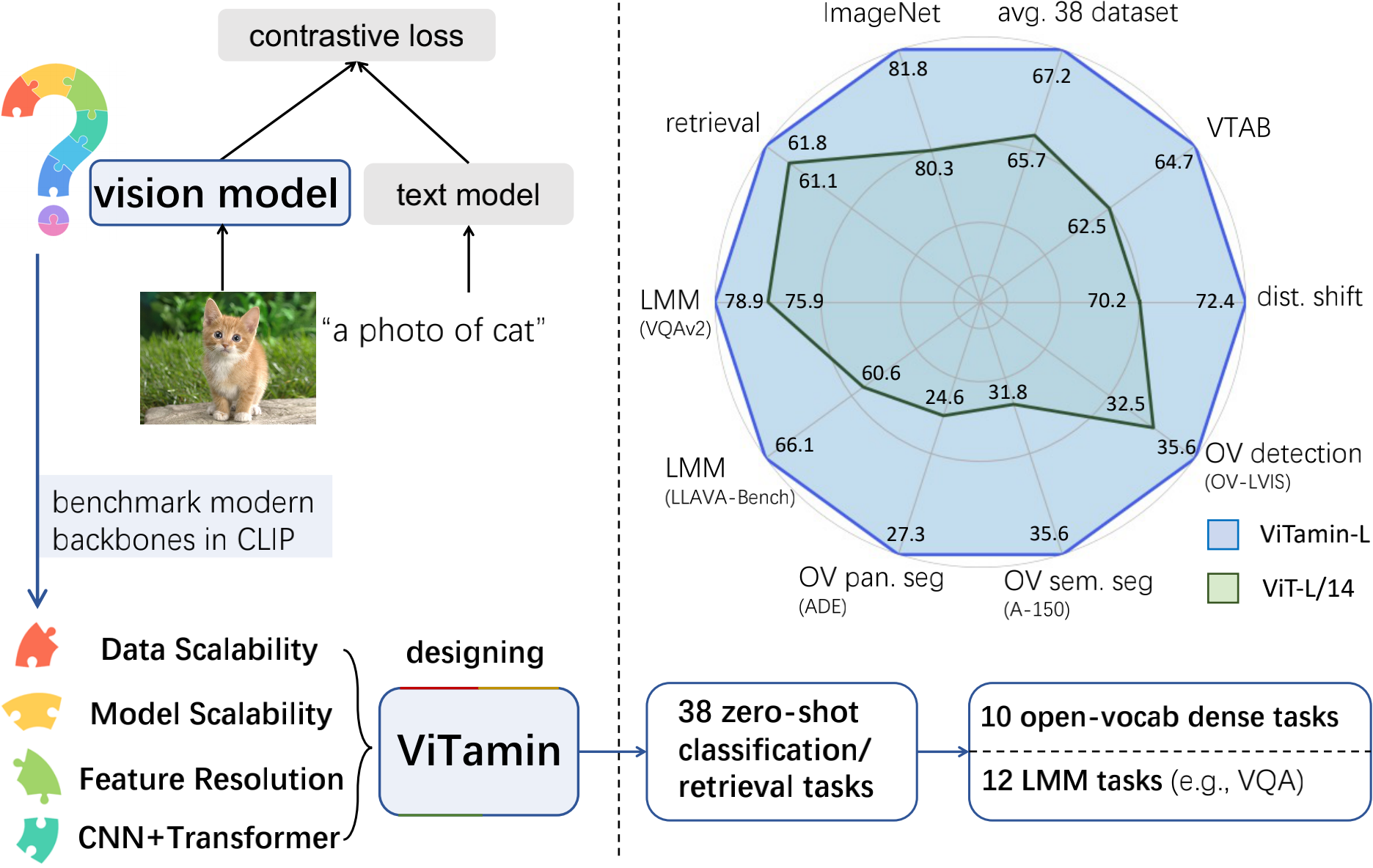
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
1. We present ViTamin, a novel scalable vision encoder in the vision-language era.
2. We benchmark modern vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework, covering their zero-shot performance and scalability in both model and training data sizes.
3. ViTamin achieves new state-of-the-art results across a spectrum of benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal model etc., significantly surpassing competing methods.
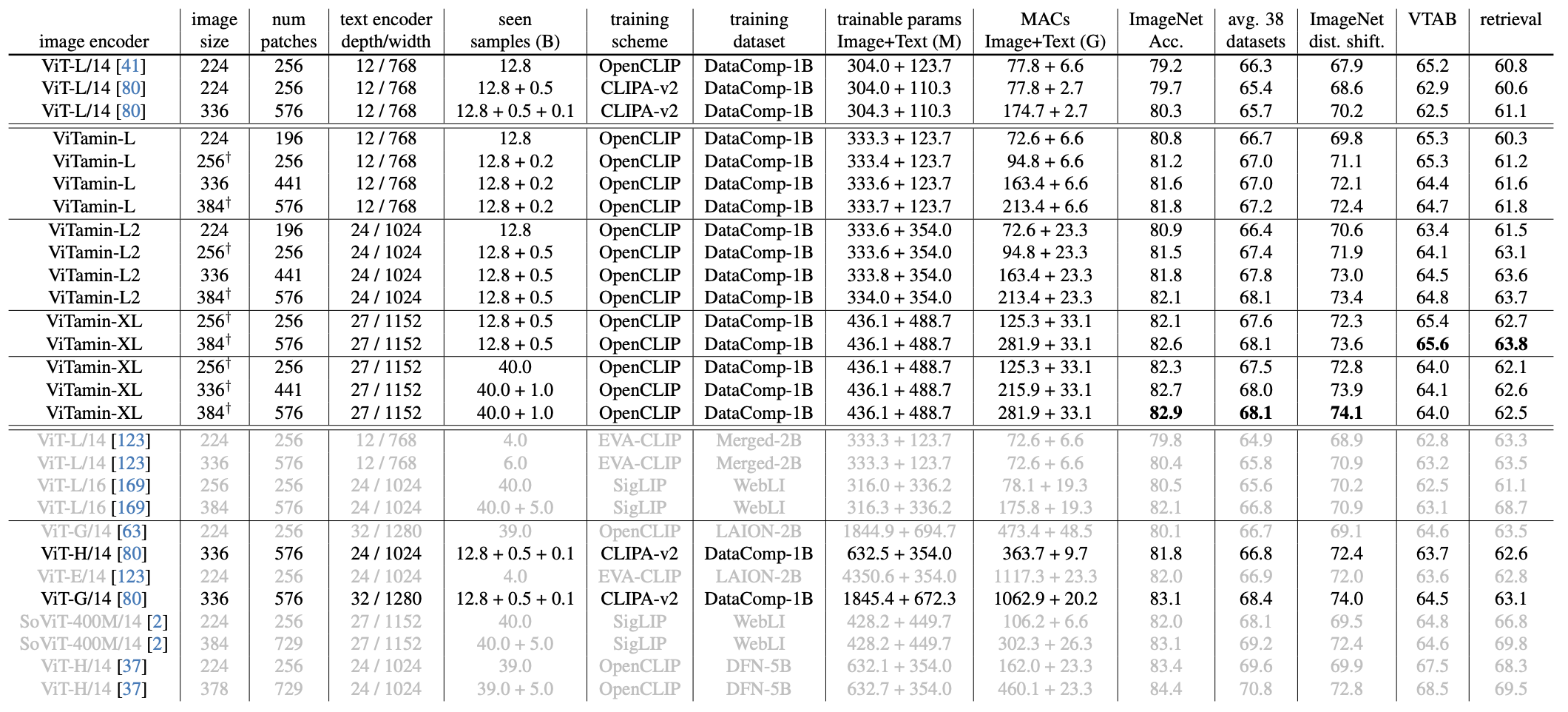
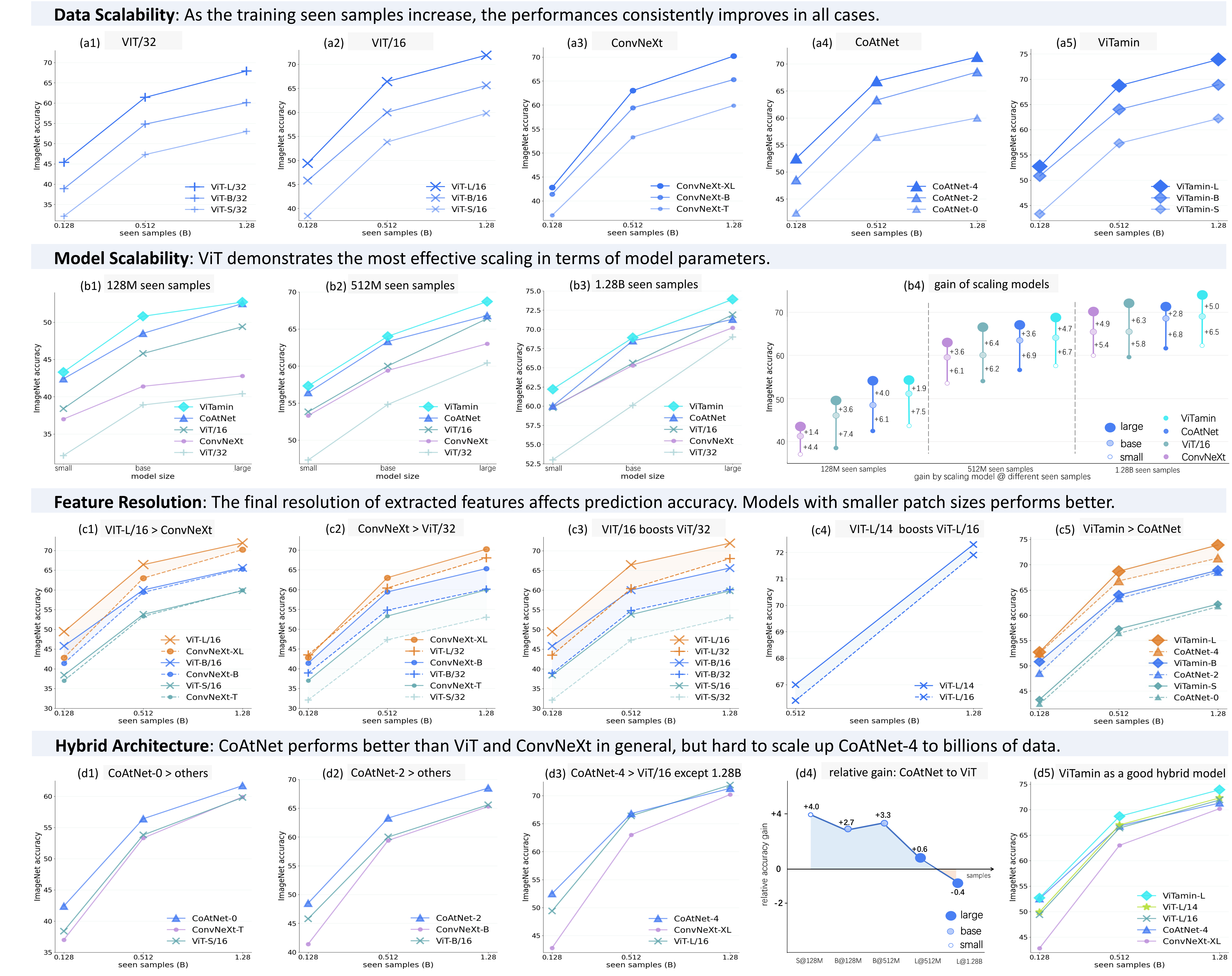
We benchmark vision models under CLIP setting on DataComp-1B, including ViT (a pure Transformer), ConvNeXt (a pure ConvNet), and CoAtNet (a hybrid model). We examine their scalability in terms of both data sizes (1st row) and model scales (2nd row), and further analyze the results from the aspects of feature resolution (3rd row) and hybrid architecture (4th row).
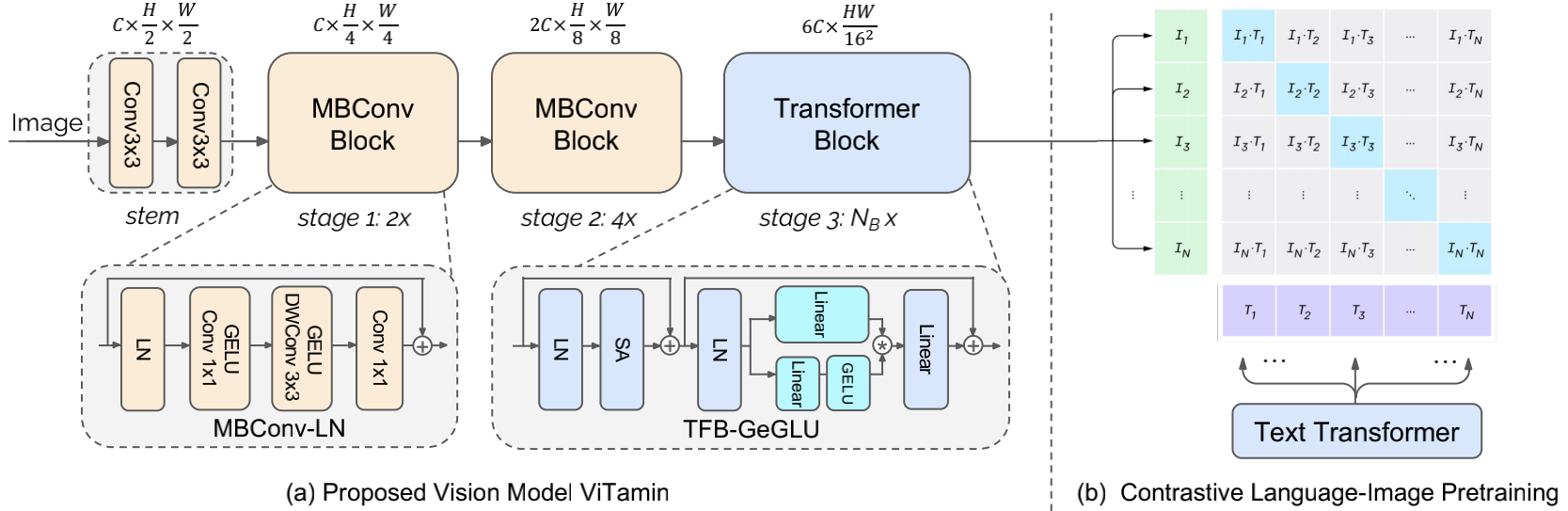
Overview of ViTamin architecture. ViTamin begins with a convolutional stem (i.e., two 3x3 convolutions), followed by Mobile Convolution Blocks (MBConv) in stage 1 and 2, and Transformer Blocks (TFB) in stage 3. The 2D input to the stage 3 is flattened to 1D. For the macro-level designs, the three-stage layout generates the final feature map with output stride 16, similar to ViT/16. We set channels sizes for the three stages to be (\(C\), \(2C\), \(6C\)) that is empirically effective. For the micro-level designs, the employed MBConv-LN modifies MBConv by using a single LayerNorm. Unlike the original Transformer Block (TFB), the adopted TFB-GeGLU upgrades its FFNs (Feed-Forward Networks) with GELU Gated Linear Units.
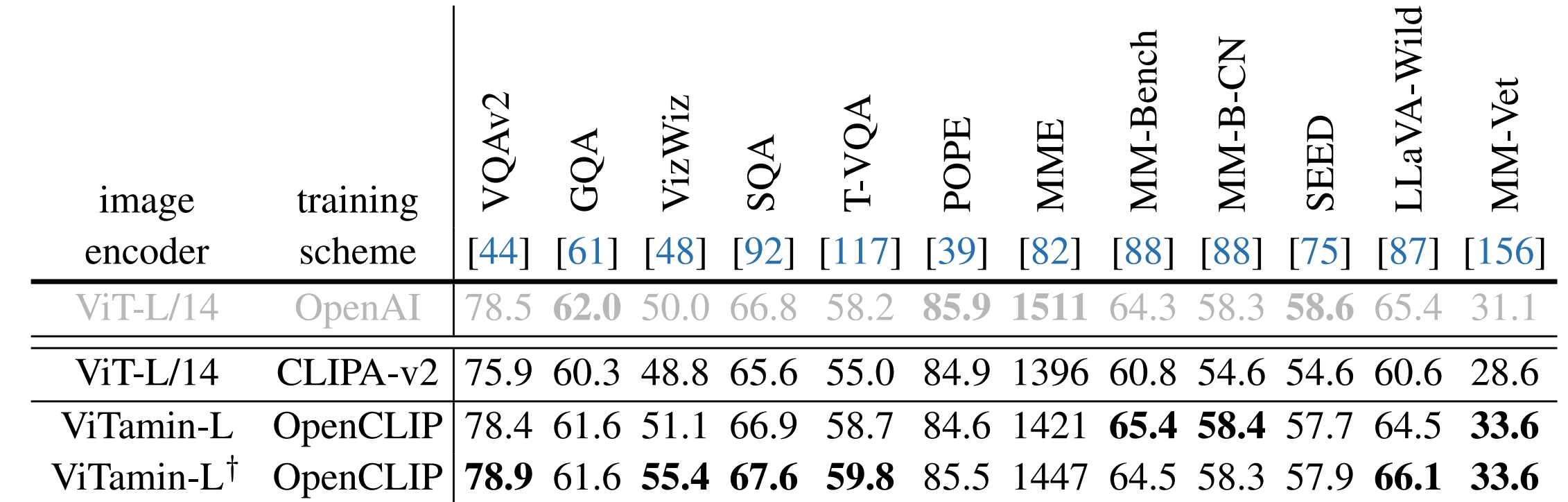
ViTamin achieves new state-of-the-art results across a spectrum of benchmarks, including zero-shot classification and retrieval, open-vocabulary detection and segmentation, and large multi-modal model etc.


@inproceedings{chen2024vitamin,
title={Design Scalable Vision Models in the Vision-language Era},
author={Chen, Jieneng and Yu, Qihang and Shen, Xiaohui and Yuille, ALan and Chen, Liang-Chieh},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}